Understanding Ontologies Through Pizza: A Beginner’s Guide (Part 1)
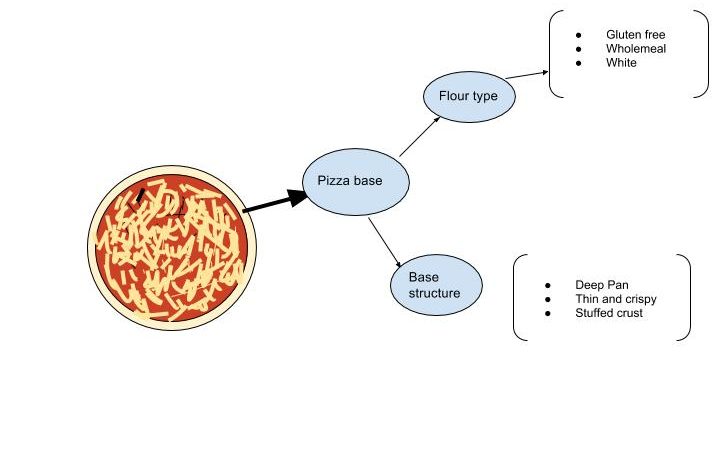
Understanding Ontologies Through Pizza: A Beginner’s Guide (Part 1) Why This Matters? Ever wondered how AI systems understand that a Margherita is a type of pizza, not just a random word? Or how recommendation engines know which wines pair with which foods? The answer lies in ontologies—the structured knowledge frameworks that help machines understand our world the way humans do. In this series, we’ll build that understanding from scratch using everyone’s favorite example: pizza 🍕 . What Exactly Is an Ontology? Think of an ontology as a sophisticated family tree—but instead of people, it organizes concepts and their relationships. Formal definition: An ontology is an explicit, formal specification of concepts in a domain and the relationships among them. It’s the difference between a computer storing “Margherita” as random text versus understanding it as a specific type of vegetarian pizza with tomato sauce, mozzarella, and basil. Real-World Impact Ontologies power: Medical systems (SNOMED, UMLS) that help doctors share patient information E-commerce platforms (like Amazon’s product categorization) Semantic Web technologies that make information machine-readable Enterprise knowledge graphs that connect business data The global ontology market is projected to reach $2.1 billion by 2028, driven by AI and semantic search needs. The Pizza Ontology: Your Learning Companion We’re using the Pizza Ontology—originally developed for teaching knowledge representation—because it’s: Universally relatable (everyone knows pizza) Sufficiently complex (enough variations to demonstrate key concepts) Beginner-friendly (no specialized domain knowledge required) By the end of this series, you’ll understand how to model any domain from healthcare to finance. Core Building Blocks: Classes, Properties, and Instances 1. Classes: The Categories Classes represent types or categories of things. They answer: “What kinds of things exist in this domain?” In our Pizza Ontology: Pizza ├── VegetarianPizza ├── MeatPizza └── CheeseTopping ├── MozzarellaTopping └── ParmesanTopping Key insight: Classes form hierarchies using “is-a” relationships. A MargheritaPizza is a VegetarianPizza, which is a Pizza. 2. Properties (Slots): The Relationships Properties describe characteristics and connections. They answer: “What can we say about these things?” Pizza properties include: hasTopping (connects pizza to toppings) hasBase (thin crust, thick crust, etc.) hasCalorieContent (nutritional info) 3. Instances: The Real Things Instances are actual examples of classes: Dominos_Margherita_Large (a specific pizza) MozzarellaTopping (a specific cheese type) Class vs Property: The #1 Beginner Mistake ❌ Common error: Making everything a class Should “spicy” be a class or a property? ✅ Correct approach: SpicyTopping is a class (a type of topping) hasSpiceLevel is a property (describes intensity: mild/medium/hot) Rule of thumb: If something has independent existence and you can list examples, it’s likely a class. If it describes or relates other things, it’s a property. Why Structure Matters: Constraints and Validation Ontologies don’t just organize—they enforce meaning: Example: Disjoint Classes MeatTopping ⊥ VegetarianTopping This means no topping can be both meat and vegetarian simultaneously. Try to create “vegetarian pepperoni” and the system catches the contradiction. Example: Cardinality Constraints A pizza must have exactly 1 base A pizza can have 0 or more toppings A Four Cheese pizza must have at least 4 cheese toppings These rules prevent nonsensical data like “baseless pizza” or mislabeled products. Competency Questions: Your Design North Star Before building any ontology, define what questions it should answer: For Pizza Ontology: Which pizzas are strictly vegetarian? Which pizzas have at least two cheeses? What toppings never appear together? Which pizzas are suitable for lactose-intolerant customers? What’s the average calorie content of meat pizzas vs vegetarian pizzas? Your ontology’s structure flows from these questions—not the other way around. Protégé: Your Ontology Workshop We’ll use Protégé, the industry-standard open-source editor developed at Stanford. Think of it as: A visual class hierarchy builder A constraint validator A reasoning engine tester Why Protégé? Free and widely adopted in academia and industry Works with OWL (Web Ontology Language) standard Has powerful reasoners (HermiT, Pellet) that check consistency The Power of Reasoning: Making Machines Think Here’s where ontologies become magical: You define: VegetarianPizza = Pizza AND hasTopping ONLY VegetarianTopping MargheritaPizza = Pizza AND hasTopping {Mozzarella, Tomato, Basil} The reasoner infers: “Since Margherita only has vegetarian toppings, it must be a VegetarianPizza”—even if you never explicitly said so. This automated classification scales to thousands of concepts, catching errors humans would miss. Preview: What’s Next in This Series Part 2: Hands-on: Building the Pizza Ontology in Protégé Part 3: Advanced Modeling: Restrictions, Properties, and Design Patterns Part 4: From Ontology to Knowledge Graph: Loading into Neo4j Part 5: Querying and Reasoning: Making Your Ontology Work Key Takeaways ✅ Ontologies = Shared vocabulary + Formal structure + Machine-interpretable definitions ✅ Three core elements: Classes (types), Properties (relationships), Instances (examples) ✅ Design with purpose: Start with competency questions, not arbitrary categories ✅ Constraints enable validation: Your ontology should catch mistakes, not just organize data ✅ Reasoning unlocks power: Well-designed ontologies make implicit knowledge explicit Your Turn: Quick Exercise Before moving to Part 2, try this thought experiment: Model a “sandwich ontology”: What are the main classes? (Sandwich, Bread, Filling, etc.) What properties connect them? (hasBread, hasFilling, isVegetarian) Write 3 competency questions your ontology should answer Identify one pair of disjoint classes (Share your answers in the comments—I’ll feature the best designs!) Resources 📄 Ontology Development 101 – Stanford Guide🛠️ Download Protégé🍕 Pizza Ontology on GitHub Next: [Part 2 – Building Your First Pizza Ontology in Protégé →] Found this helpful? Follow for Parts 2-5 where we’ll build, query, and deploy a working knowledge graph! Tags: #Ontology #KnowledgeGraphs #SemanticWeb #AI #MachineLearning #DataScience #OWL #Protégé #KnowledgeRepresentation About This Series This is Part 1 of a 5-part series demystifying ontologies through practical examples. Whether you’re a data scientist, software engineer, or domain expert, you’ll learn to build structured knowledge that machines can reason over.
